
You probably want your bot to look as human as possible. And a key characteristic of (many) humans is their empathy, i.e. the ability to understand the feeling of the person we are talking to and to adapt our response to those feelings.
I want my chatbots to show the same level of empathy. And for that, the key ingredient is a sentiment analysis feature that helps the bot detect whether the user is happy or not. Or, in more technical terms, whether the sentences she is writing have a positive or a negative tone. It would be even better if we could detect also whether he is sad, or joking or …. but, as usual in any type of classification problem, the more categories you define the more difficult is the classification.
I’m happy to say that we have now added sentiment analysis capabilities to Xatkit. It’s implemented as one of our brand new Processor mechanism. Processors are additional pieces of logic that can be plugged to tune the intent recognition process. Pre-processors operate on the user input to optimize it before intent extraction. Post-processors are designed to operate after the intent recognition process, usually to set additional context parameters. Sentiment analysis is one of such post-processors (we’ll talk about other processors in future posts). This allows us to tune the chatbot response to how the user is feeling.
Keep your visitors engaged in the conversation by adapting your response to their emotional state
But we didn’t want to implement such a complex feature from scratch. Instead, as Xatkit’s core is written in Java, we searched for existing Java libraries that we could reuse. And here is where the wonderful Stanford CoreNLP project, and in particular the SentimentAnnnotator component, came to the rescue. Stanford NLP annotates an input text with 5 classes of sentiment classification: very negative, negative, neutral, positive, and very positive. To do so, it relies on a Recursive Neural Network pre-trained with its own sentiment treebank.
This may sound complicated but I promise it’s not. All the code showing how we integrated Stanford NLP in Xatkit is available in this Java class. Let’s see the key code excerpts so that you can build a similar integration for your own tool.
The following snippet shows how we create an Annotation object from the input text string (provided by getMatchedInput in the example; this and the session objects are internal Xatkit elements storing the user utterance and session data, respectively). From the annotation instance, we then get the set of annotated sentences (Stanford assumes we want to identify the sentiment in a block of text, not just single sentences as there may not be enough context there, though in our tests, it behaved pretty impressive even with short sentences). Finally, with get(SentimentCoreAnnotations.SentimentClass.class), we filter out other types of annotations and keep only the sentiment analysis one. This value is then added to the session information so that we can use it to decide the response action later on.
The getAnnotation method is the most important one as it’s here where we are actually asking Stanford NLP to run its analysis on our input data. In our code, we have wrapped the call in our own StanfordNLPPostProcessor class for performance reasons. Annotating a text takes time and we wanted to make sure that we were doing it only once even if we had several processors running on the text for different reasons. As shown in the following code snippet, we make sure to call this method if and only if there is no other Annotation object already available for the same text.
Finally, the result of the analysis can be accessed through the context variable in the bot execution language, that contains a special nlp context holding the results of the different StanfordNLP-related post-processors (sentiment analysis, but also whether a question is a yes/no question, etc). The code below is actually a real-world example from our own bot!
Don’t forget you can give it a try by just moving to our home page. See an animation of the sentiment test in our demo:
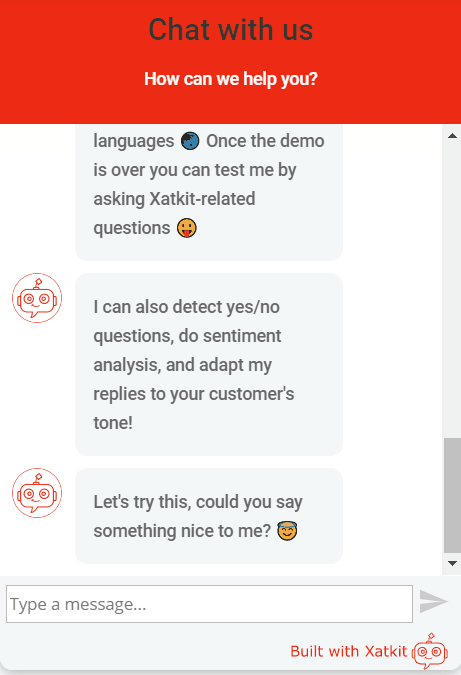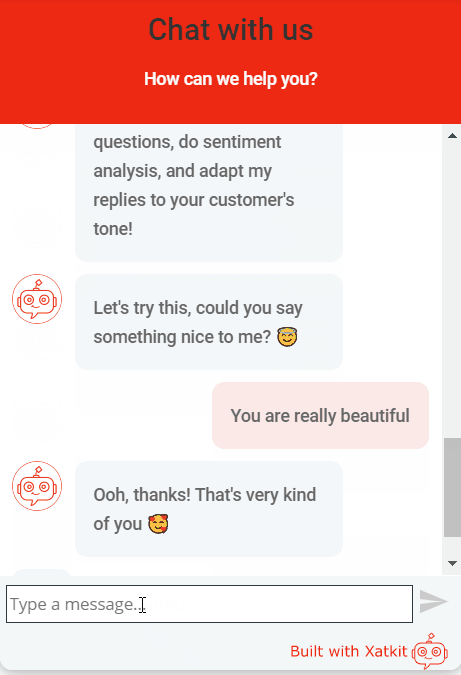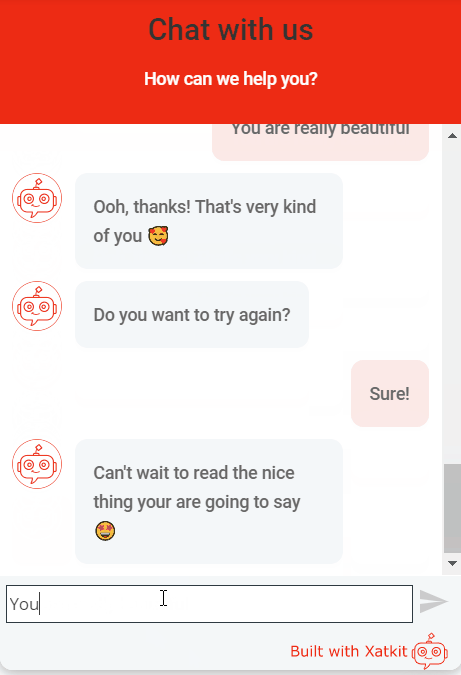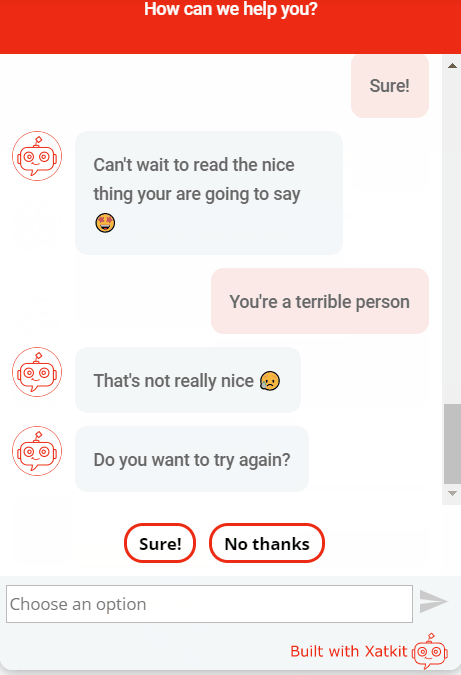
I hope we managed to convince you that adding a Sentiment Analysis capability to your tool is worth your time. And this is just the beginning, beyond sentiment analysis (and the other available Processors), we believe there are plenty of other opportunities that could make chatbots much better in understanding the users. Even to prevent the bot from trying to match the utterance at all. I’m thinking, for instance, in a pre-processor for toxic comments (e.g. see one for WordPress comments) or a troll detector. This can also prevent you from wasting valuable resources (including money if you’re using a cloud-based API for the matching phase) by NOT processing user utterances that can just be thrown away.
