I’m sure you often get questions from your visitors and think “but this is already on the website!”. You then added a chatbot to your site to filter out the most common questions. But what about all the rest. Adding more and more questions to the bot it takes time. So, is there an easy way to let the chatbot find the answer by itself for those questions that are already answered somewhere in the (hundreds? thousands?) pages, posts or other online documents you’ve already published?
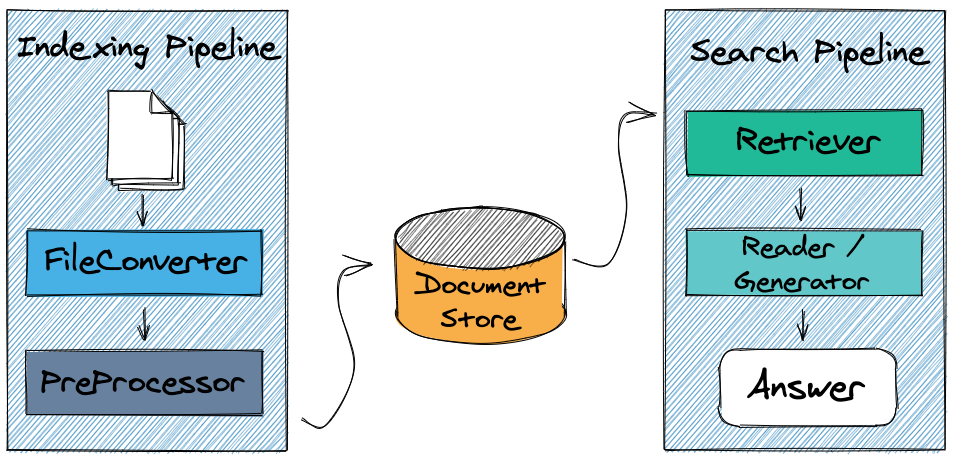
YES!. The key is to plug Haystack to your chatbot. We have several pretrained language models fine-tuned for Question Answering that can be used to find an answer in a text but they only work when the text length is really small. Here it is where Haystack comes into play. Haystack architecture (see the featured image above) proposes a two-phase process:
- A Retriever selects a set of candidate documents from all the available information. Among other options, we can rely on ElasticSearch to index the documents and return those that most likely contain the answer to the question
- A Reader applies state-of-the-art QA models to try to infer an answer from each candidate
Now we just need to return these inferred solutions together with additional information (context, confidence level,…) to help our users understand why we think this is the answer they were looking for. All thanks to a completely free and open source NLP framework!
Let’s see how we can benefit from Haystack by creating a chatbot able to answer software design questions for the WordPress website modeling-languages.com. Haystack website is full of useful examples, so we’ll adapt them in our scenario.
Creating the chatbot, the “front-end”
The easiest part is to create the chatbot. We’ll obviously use Xatkit for this. The bot can have as many intents as you wish. The only part that we care about here is the default fallback state. Here, instead of saying something useless, e.g. “sorry I didn’t get your question, can you rephrase it and try again?”, we will ask Haystack to find us a solution.
Here we have all the pieces locally deployed but obviously each of them could be in a different server.
Loading the information to ElasticSearch
Before we can find an answer, we need to first power up ElasticSearch with the documents we want to use as information source for the bot. In this example, the documents will be all posts published in modeling-languages. We assume we have direct access to the WordPress database but otherwise we could write something similar using the WordPress REST API instead. Note that we split each post in different paragraphs to avoid chunks of text that could be too much for the QA models.
I deployed a Flask server to facilitate calling all the endpoints on-demand, especially needed for those that the bot needs to interact with.
Finding the answer
The Retriever component will look for the most promising documents in ElasticSearch (by default, using the BM25 algorithm but there are other options). The Reader will look into each candidate and try to find the right answer in it. Thanks to the predefined Pipelines provided by Haystack, putting everything together is really easy:
Once we have the answer, we create the response object that will be sent back to the chatbot. As a final step the chatbot will print this response to the user together with the URL of the post the answer comes from. This way, even if the answer is not perfect the user will have the option to go to the suggested URL.
But, does it work?
We’ve seen it’s feasible to add the Haystack infrastructure to a chatbot. But what about the quality of the answers? Are they good enough?
The answer is that it does work reasonably well. The modeling-languages website was not the easiest one to try with. It’s rather large (over 1000 posts that translate into around 8000 documents) with significant overlappings. And there are still some “legay” posts in Spanish that add to the confusion.
Let’s see a couple of examples. In the first one I ask on how can I add a business rule (i.e. constraint) to a software design model. The first answer is technically correct (indeed, constraints are written on top of models) but rather useless. The next two are exactly what I was hoping to see an answer as they suggest me to use the Object Constraint Language to specify my constraints.
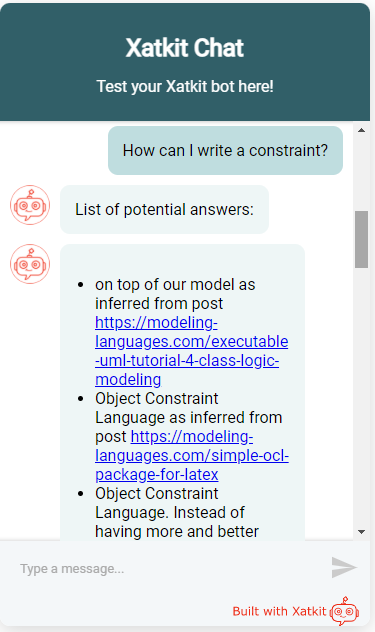
The second question is more concrete but it has a more open answer. Note that all answers are taken from the same document (the only one that realy talks about this Temporal EMF tool). All answers are reasonable but the third one really nails it. And keep in mind that we’re using an extractive QA model, meaning that the model aims to return a subset of the text containing the answer. Instead, a generative QA model (also available in Haystack) would be able to “build” the answer from partial answers, potentially spread out in more than document.
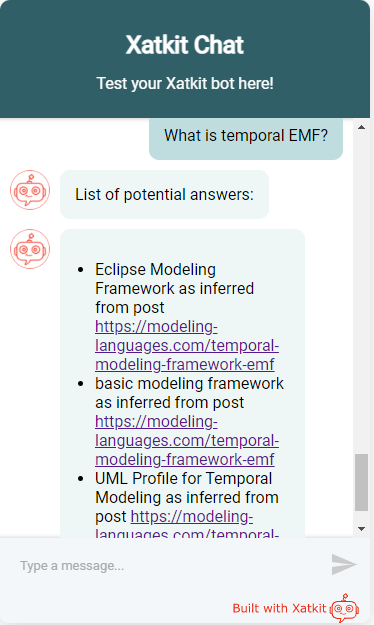
In terms of performance, results were very satisfactory. The whole process took just a few seconds (once the initial model loading) but this is on my poor laptop. With proper configuration and tuning, the user should not notice a major delay. Haystack itself can also be deployed as a REST API which should optimize even more the whole process. And of course, you could always let the bot designer to configure whether to use Haystack in the default fallback or not, depending on a number of factors.
And remember that if you’re interested mianly in returning an orderet set of relevant documents for the user to check out (instead of providing the “exact” answer), the Ranker is your friend. As the Reader, the Ranker executes after the Retriever and also uses pretrained language models but in this case with the goal of doing semantic analysis of the documents for sorting purposes.
